Azure Data Factory
Azure Data Engineering
February 01, 2022
Introduction
Azure Data Factory is a cloud-based data integration service that allows you to create data-driven workflows for orchestrating and automating data movement and data transformation. It is a platform for building scalable data integration solutions that allow you to ingest, prepare, transform, and process data from disparate sources at scale.
Key Concepts
Pipelines
A pipeline is a logical grouping of activities that together perform a task. It is a set of data-driven activities that are organized in a way that ensures that the data is processed in a specific order. A pipeline can be used to move data from one location to another, transform data, or perform a variety of other tasks.
Activities
An activity is a processing step in a pipeline. It represents a single processing step that can be performed by a service. There are many types of activities, such as data movement, data transformation, and control activities.
Datasets
A dataset is a named view of the data that simply points or references the data you want to use in your activities. It represents the structure of the data that is being used as input or output by the activities in a pipeline.
Linked Services
A linked service is a way to connect to external resources. It is a configuration that defines a connection to an external data source or an external data destination.
Triggers
A trigger is a set of conditions that determine when a pipeline should be run. It can be used to schedule the execution of a pipeline or to trigger the execution of a pipeline based on an event.
Types of data stores
Azure Data Factory supports a wide variety of data stores, including Azure Blob Storage, Azure SQL Database, Azure Synapse Analytics, Azure Data Lake Storage, Azure Cosmos DB, and many others.
Data Flows
Data flows are a type of activity that allows you to visually design and execute data transformations at scale. They provide a code-free way to design and execute data transformations using a visual interface.
Source and Sink Transformation
Source and sink transformations are used to read data from a source and write data to a sink. They are used to define the input and output of a data flow.
Data Movement
Data movement activities are used to move data from one location to another. They are used to copy data from one data store to another, or to move data between different data stores.
Data Transformation
Data transformation activities are used to transform data from one format to another. They are used to perform operations such as filtering, sorting, aggregating, and joining data.
Data Orchestration
Data orchestration activities are used to orchestrate the execution of other activities. They are used to control the flow of data through a pipeline.
Data Integration
Data integration activities are used to integrate data from different sources. They are used to combine data from different sources into a single data store.
Data Processing
Data processing activities are used to process data. They are used to perform operations such as data validation, data enrichment, and data cleansing.
Data Ingestion
Data ingestion activities are used to ingest data from external sources. They are used to bring data into the data factory from external sources.
Data Preparation
Data preparation activities are used to prepare data for analysis. They are used to clean, transform, and enrich data before it is used for analysis.
Summary
Azure Data Factory is a powerful tool for building scalable data integration solutions. It provides a platform for creating data-driven workflows that allow you to ingest, prepare, transform, and process data from disparate sources at scale. It is a key component of the Azure data engineering ecosystem and is widely used for building data integration solutions in the cloud.
References
Example
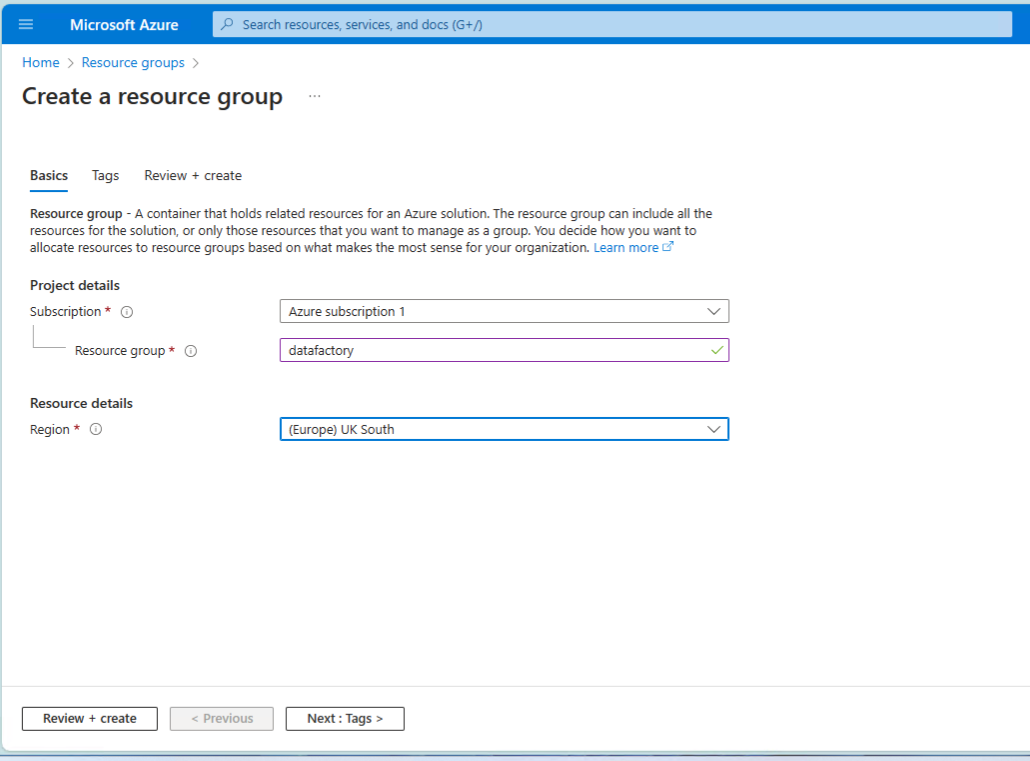
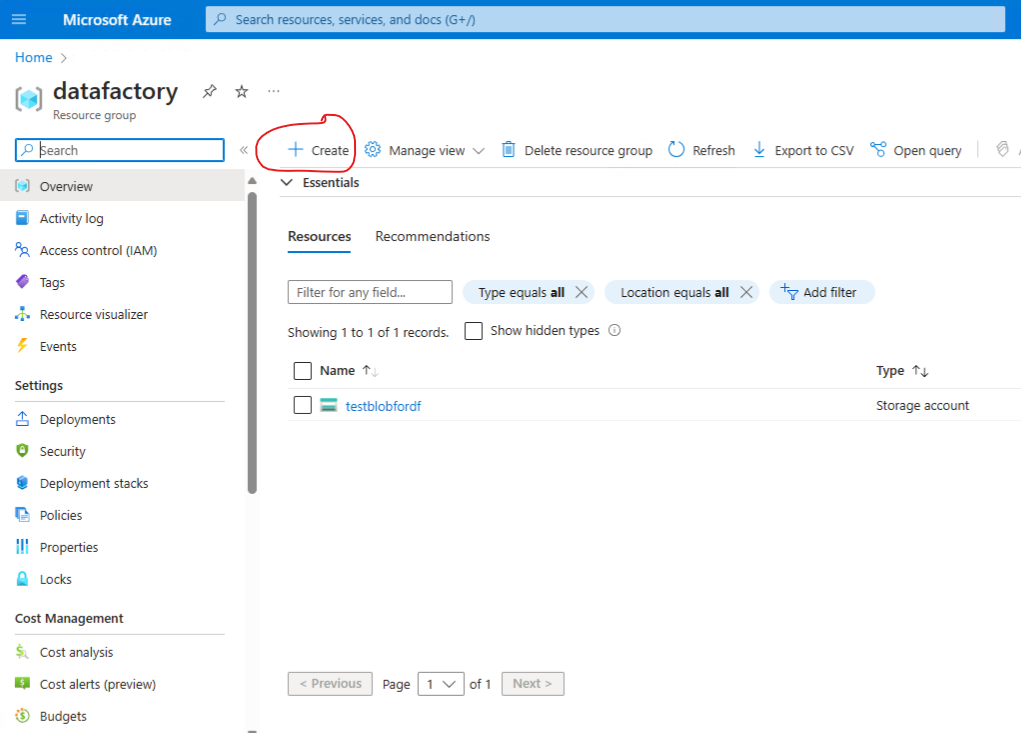
Create a resource group
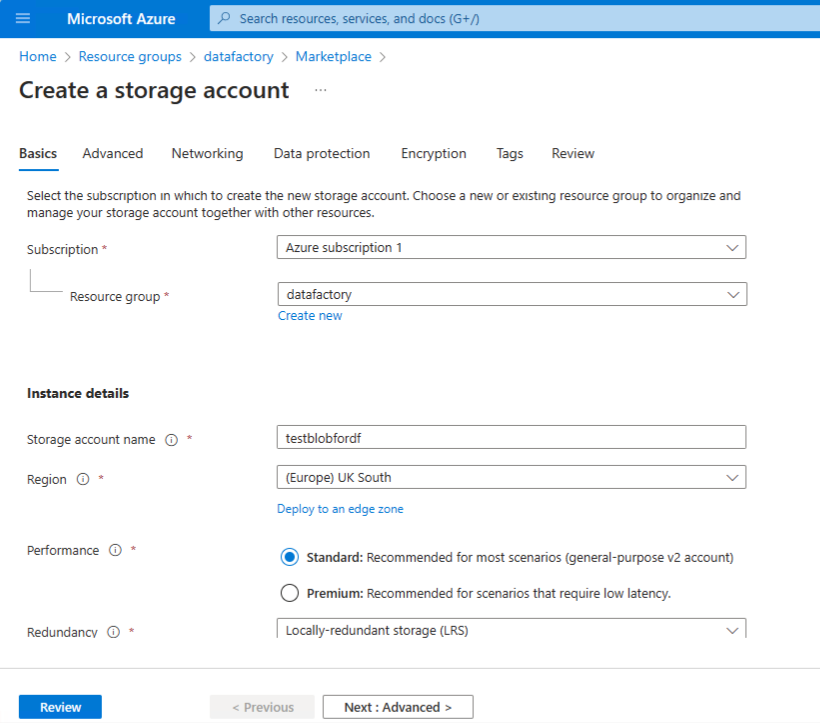
Provision a storage account and blob container
Create an azure storage accont with blob storage - as the source data store
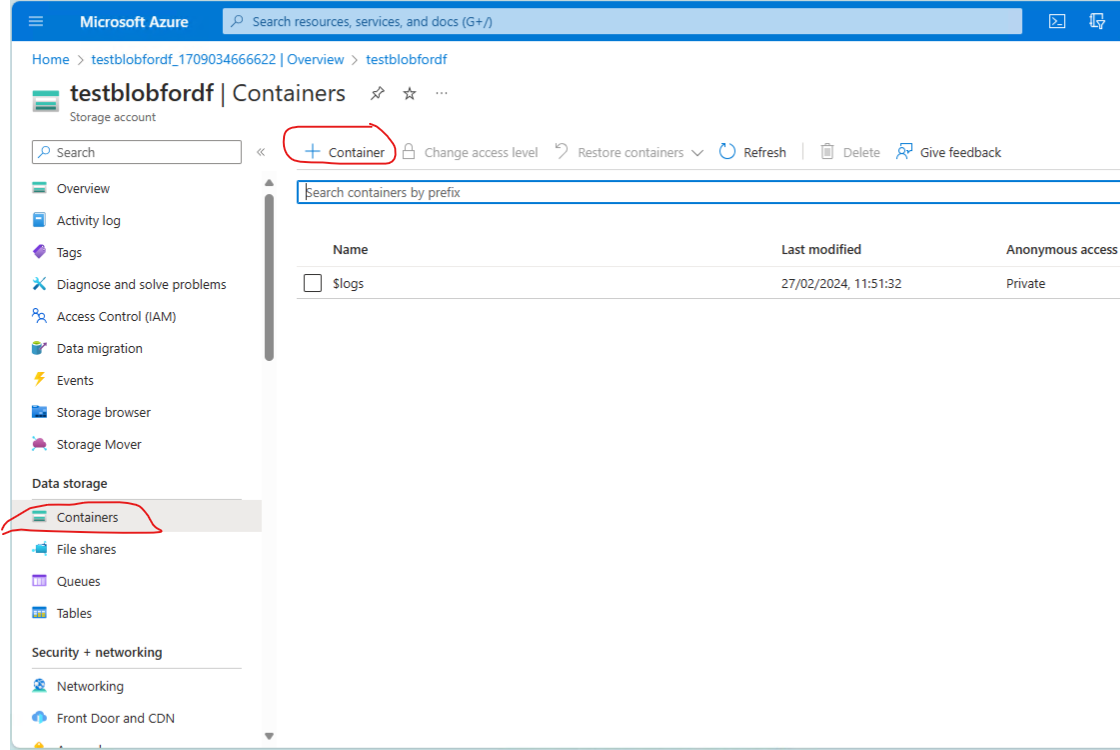
Once the storage account is provisioned - create a blob container.
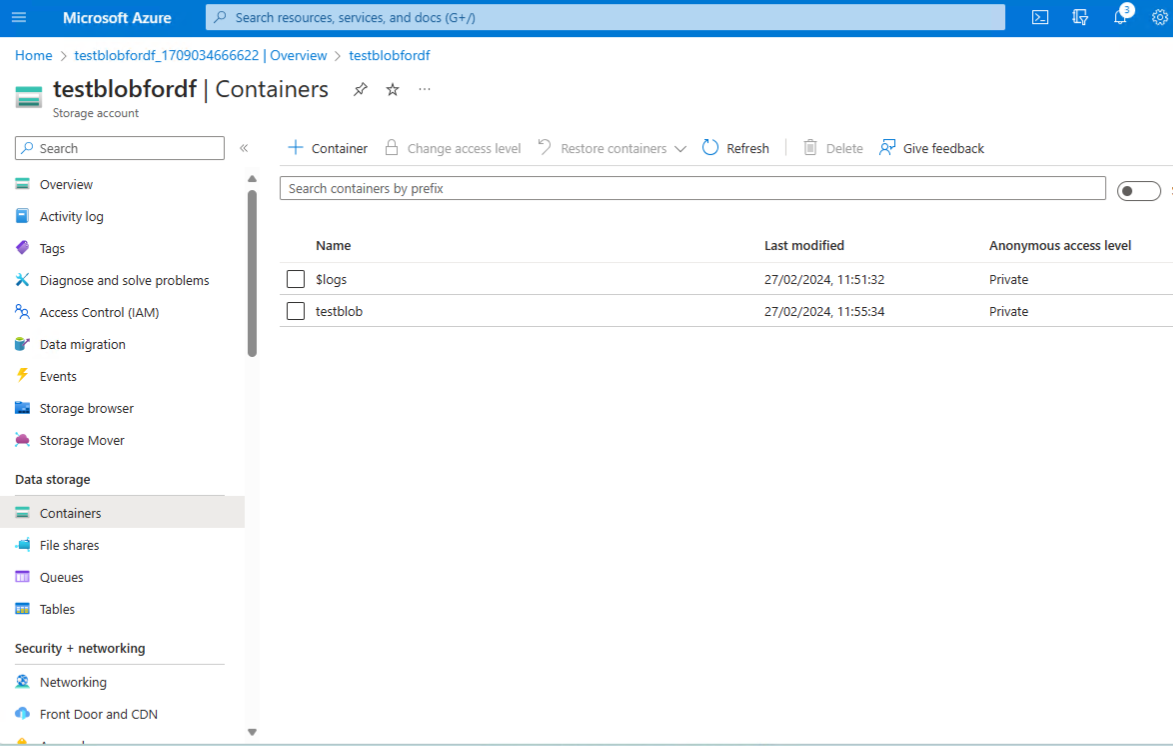
The blob container is called testblobfordf
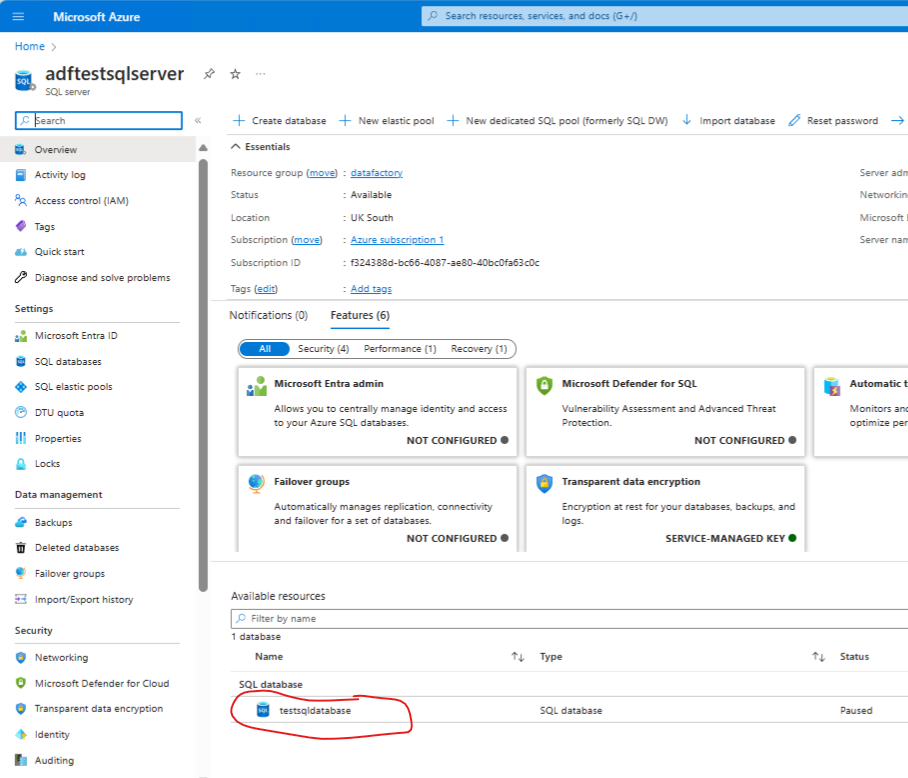
Provision an SQL database
In the same resource group create a sink data store - in this case a SQL database
In the resource group folder - ccreate a sql database
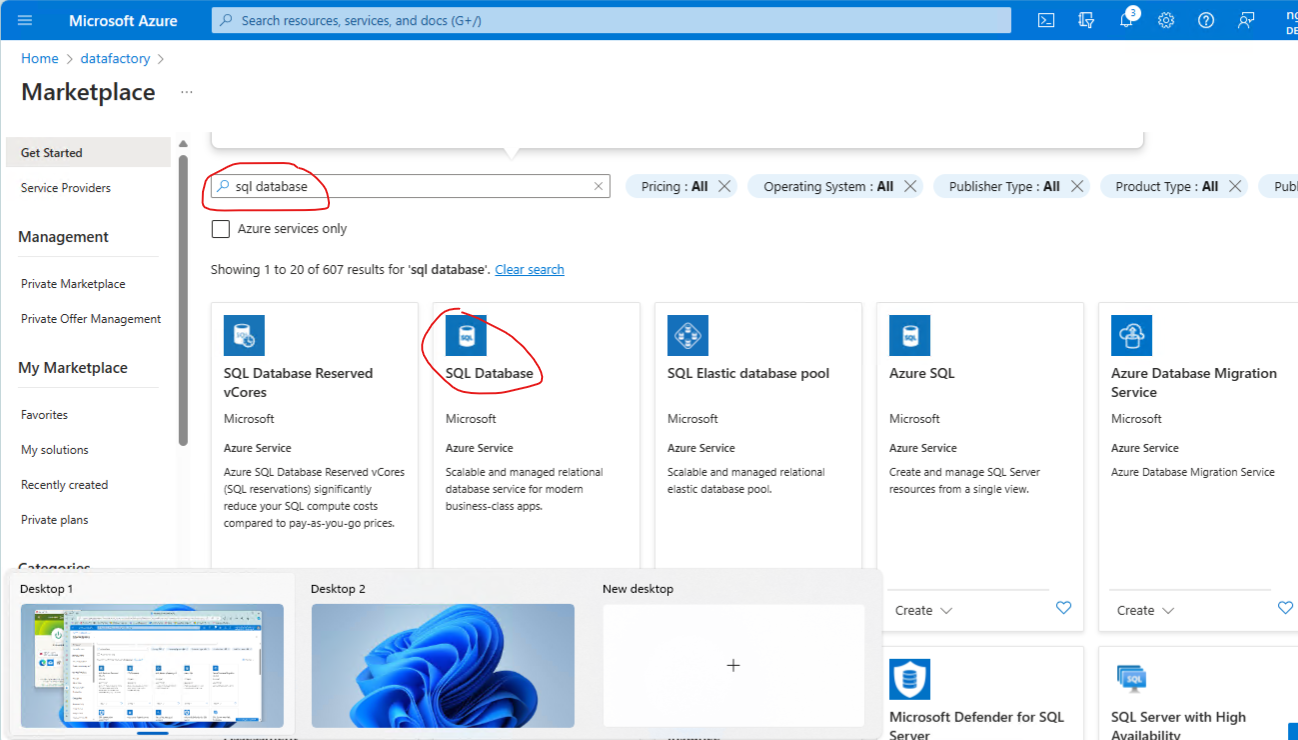
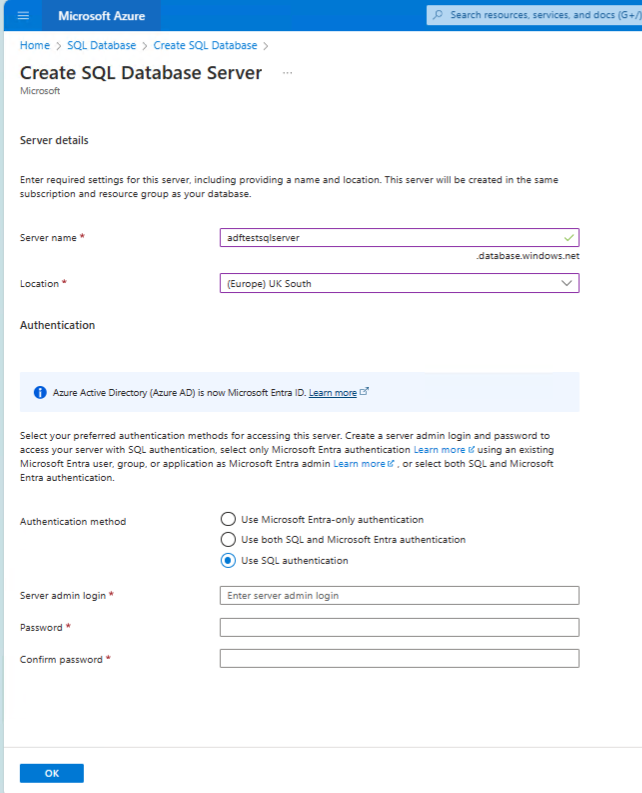
- Enter inital values - then create a database server.
- For simplicity choose sql authentication.
- Enter the login details and create the server.
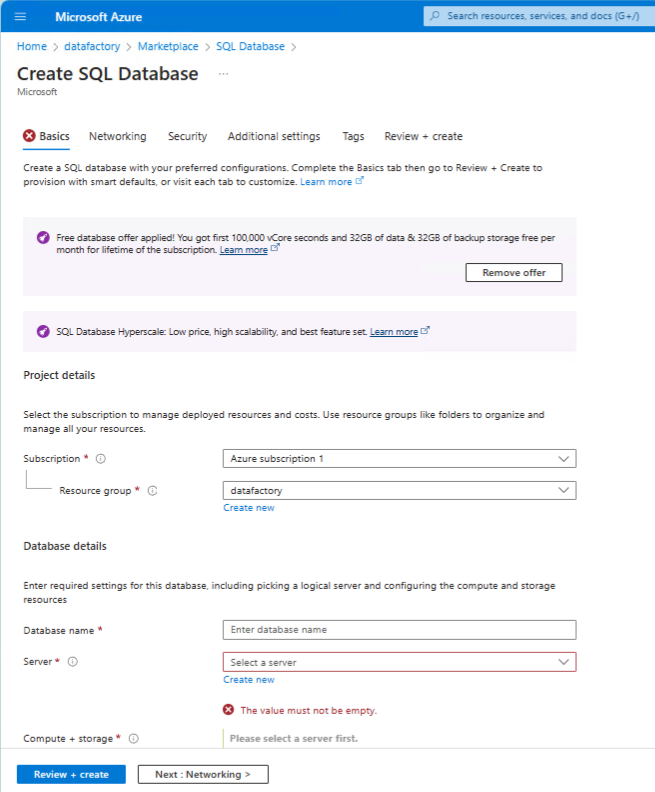
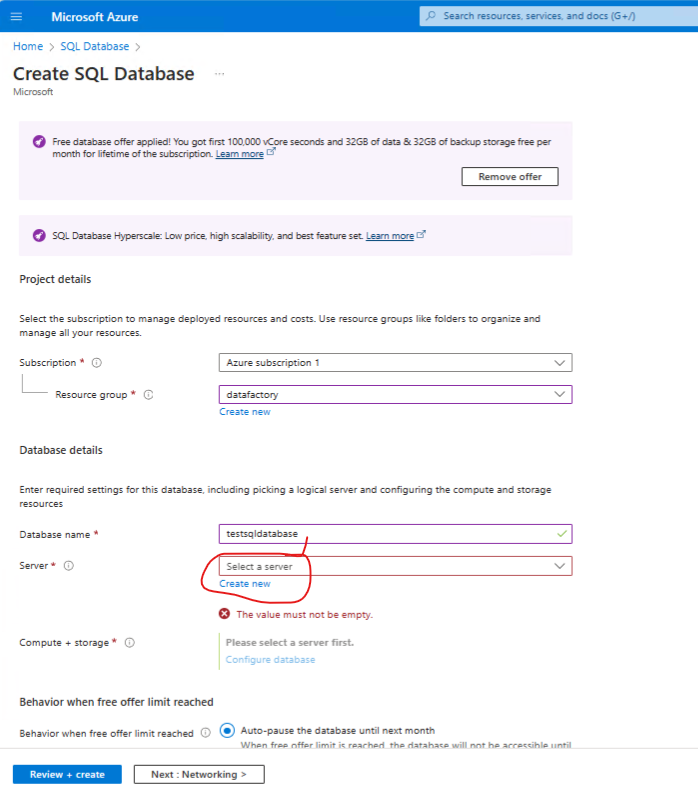
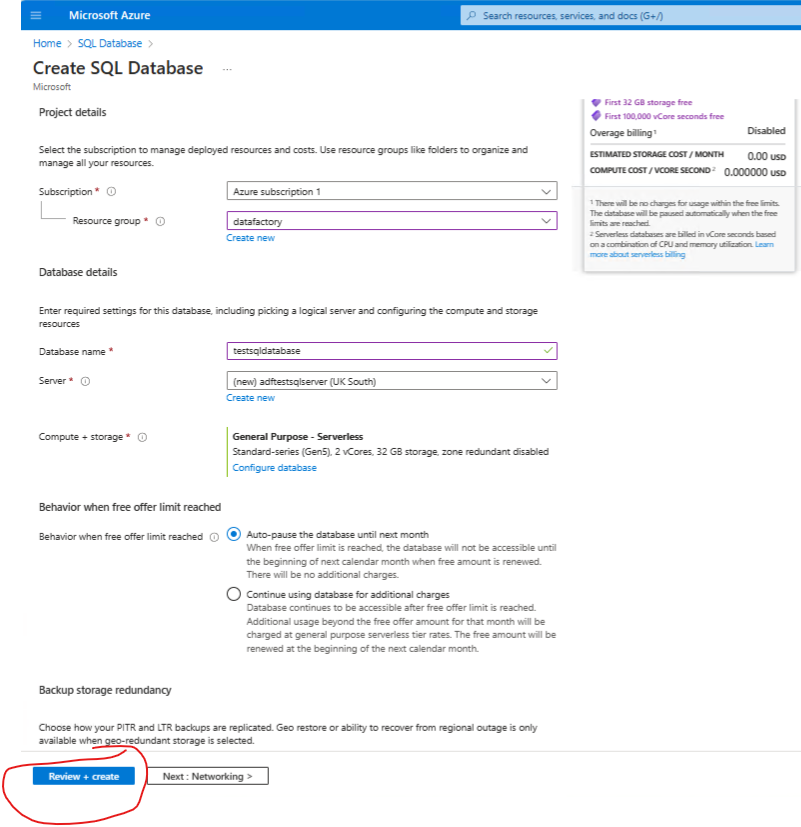
Review and create.
Prepare the SQLServer database
Once the deployment is complete click on the “go to resource “button
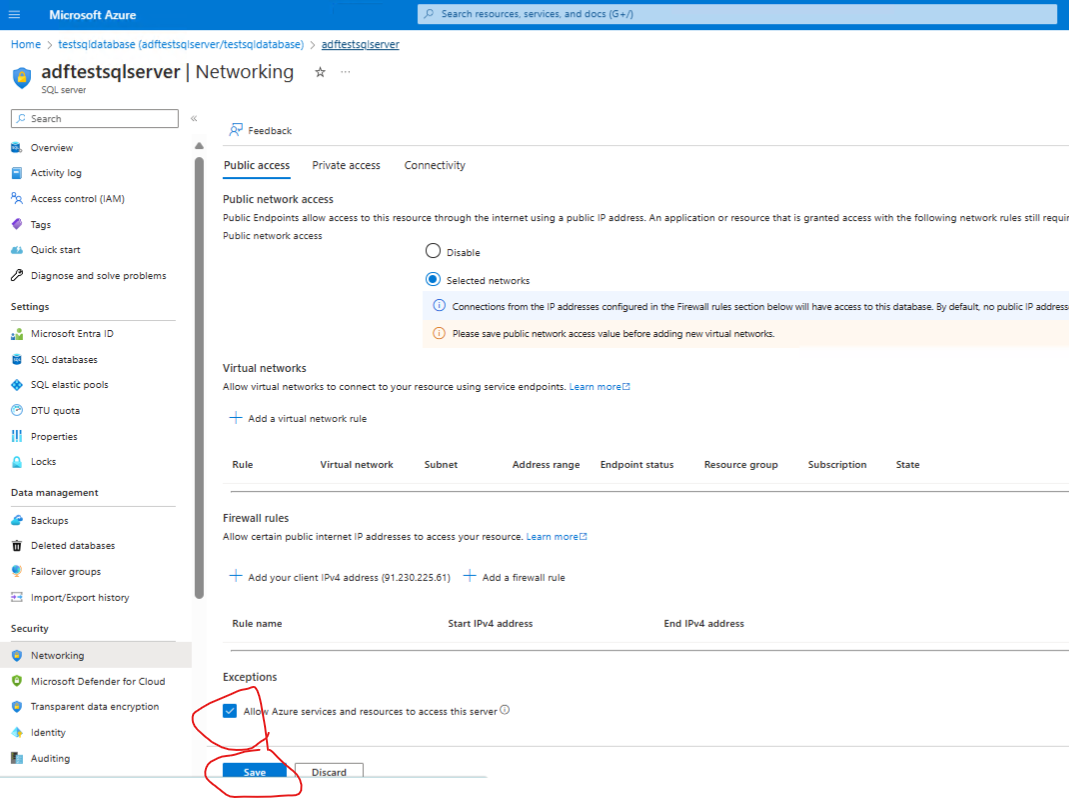
Next, go to the servers firewall settings and make sure that the Allow Azure services and resources to access this server is ticked. This will allow the data factory to write to the database.
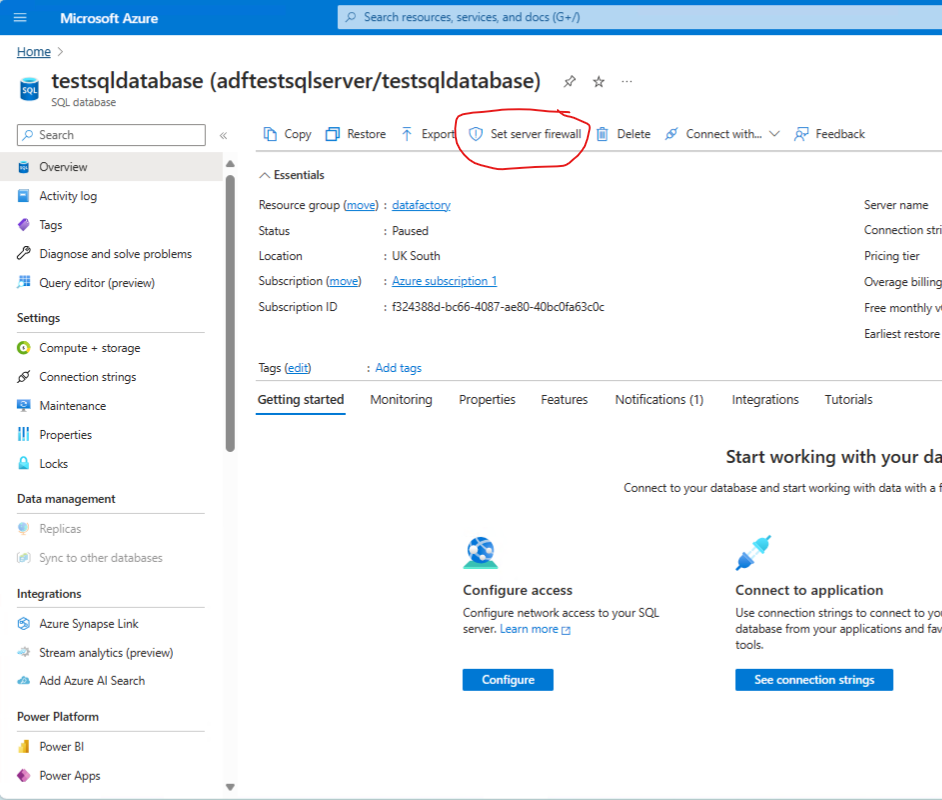
Set server Firewall > Public Access > Selected Networks.
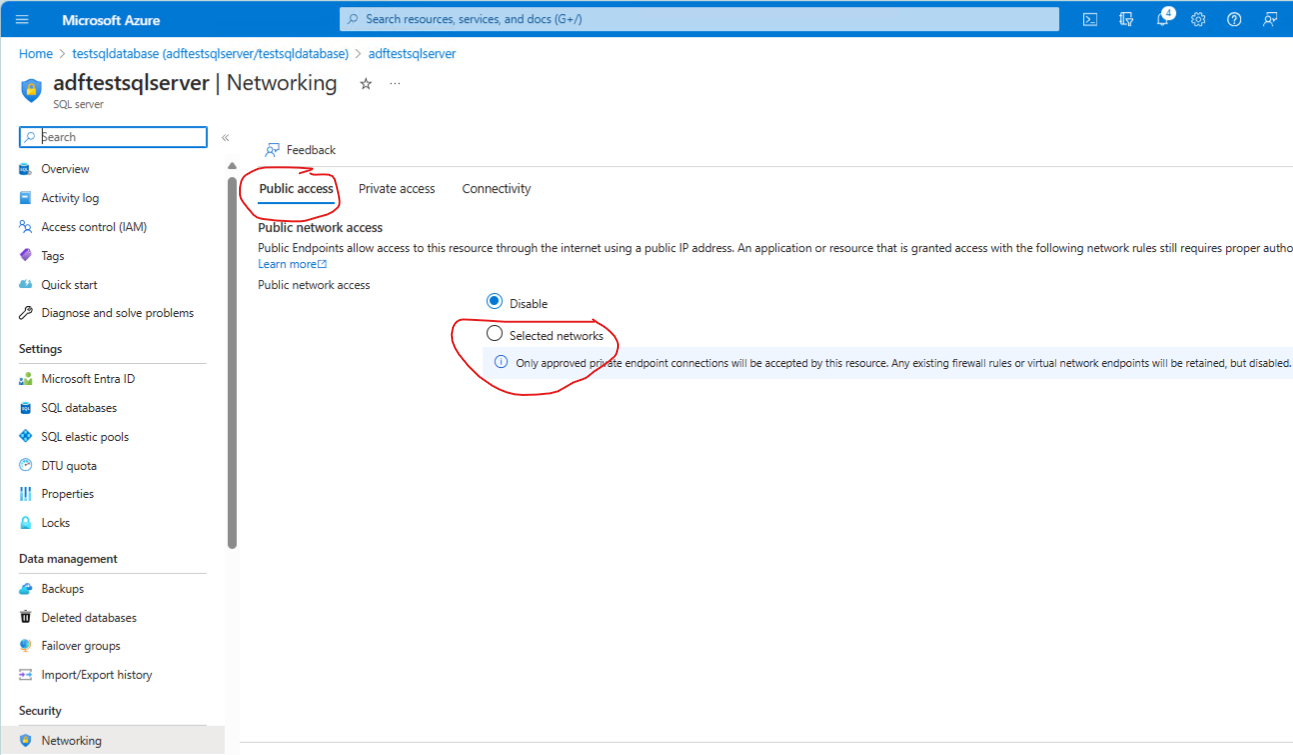
Select Save - and close the blade when done.
Create the source blob storage
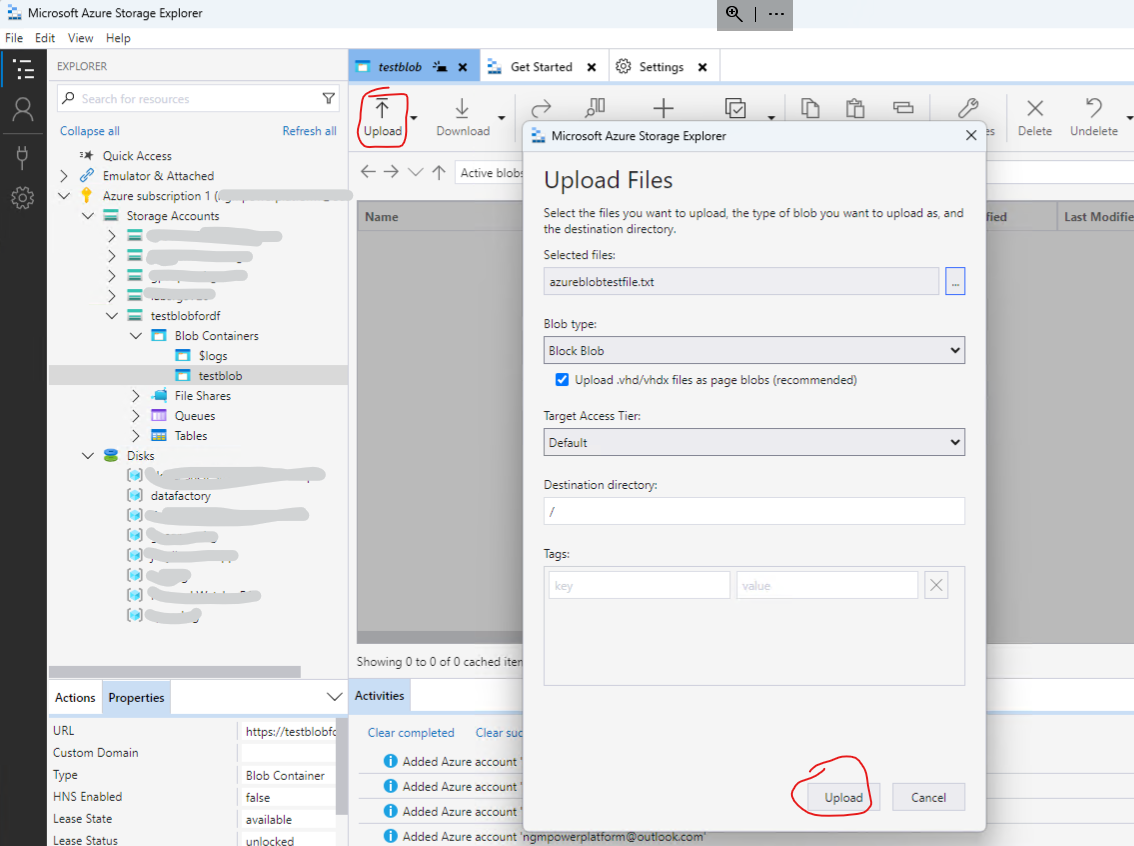
Create a local text file and use your local Azure Storage Explorer client - choose to connect to the Blob container. Make sure that you are loged into your Azure account from the Azure Storage Explorer.
The text file is called azureblobtestfile.txt and contains the following text:
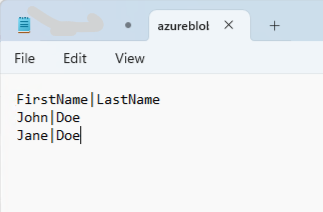
Use the Azure Storage Explorer to upload the file to the blob container created previousely - called testblobfordf.txt
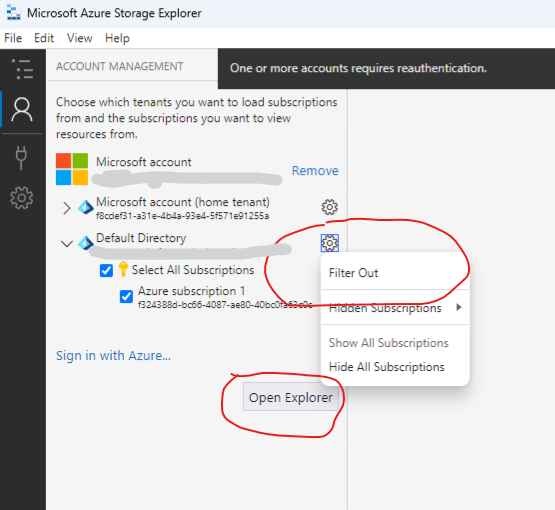
Note if your subscription is not visible you may have to first “Attach a resource” > Subscription > Azure > Next > Pick an account (sign in wiht Azure).
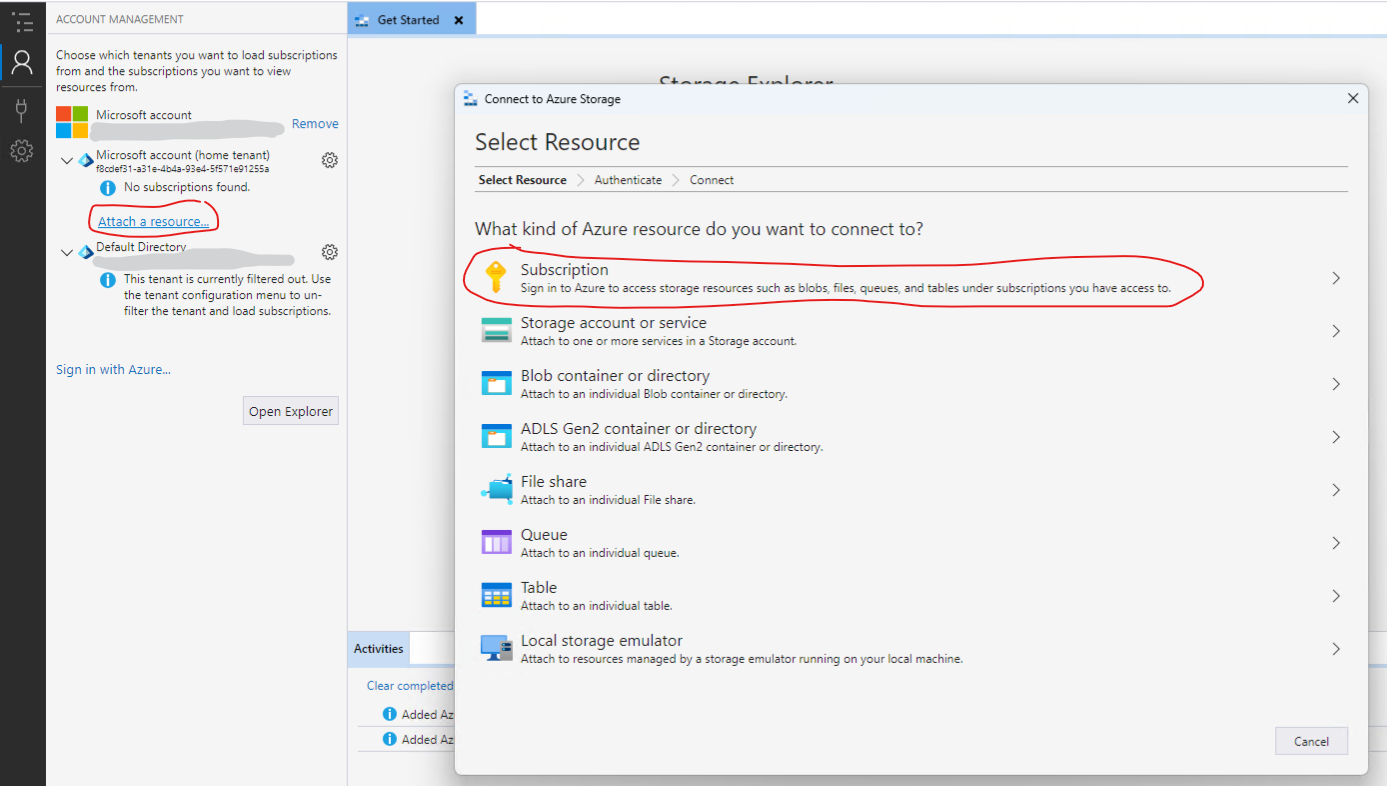
If Azure subscription not visible after signing in - then you may need to unfilter (one time code sent to your mobile phone). Unfilter to expose Default Directory Subscription
Click on Open Explorer and upload the local text file to the blob container.
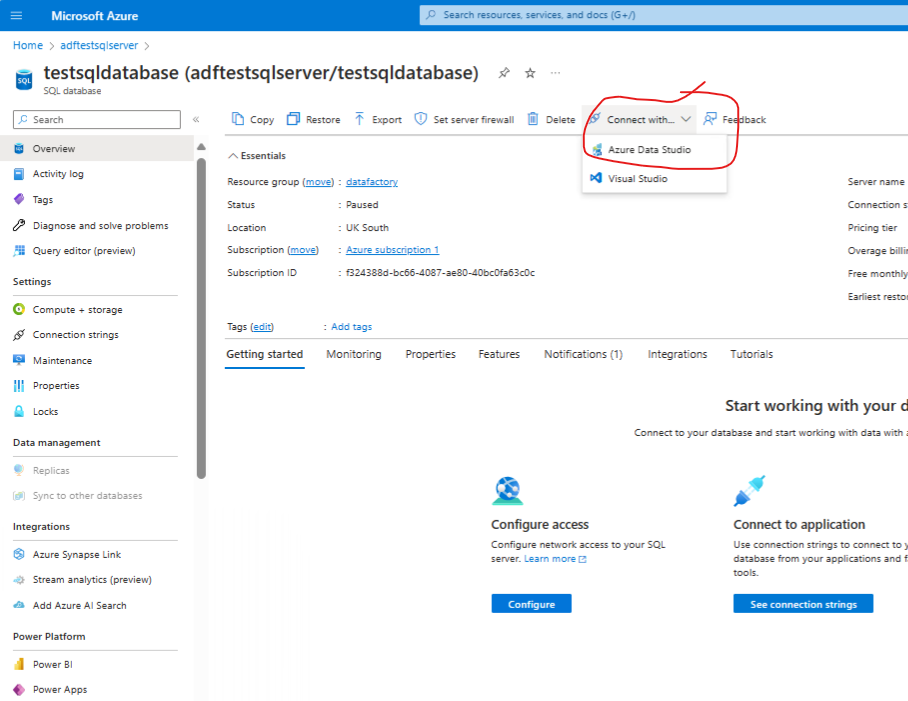
Create the sink SQL database
Next, create the sink table i.e the destination table in the SQL database.
Make sure Azure Data Studio client is installed locally - and connect to the SQL database
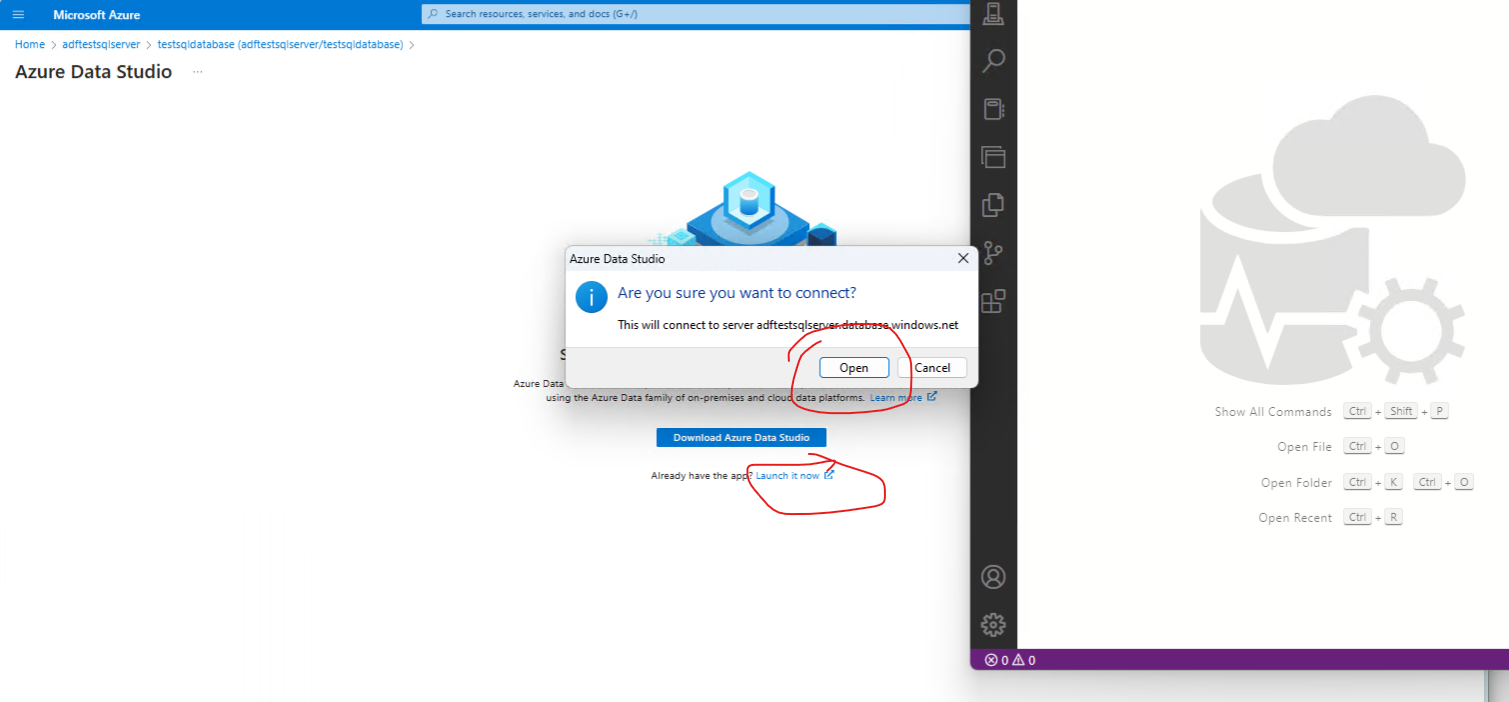
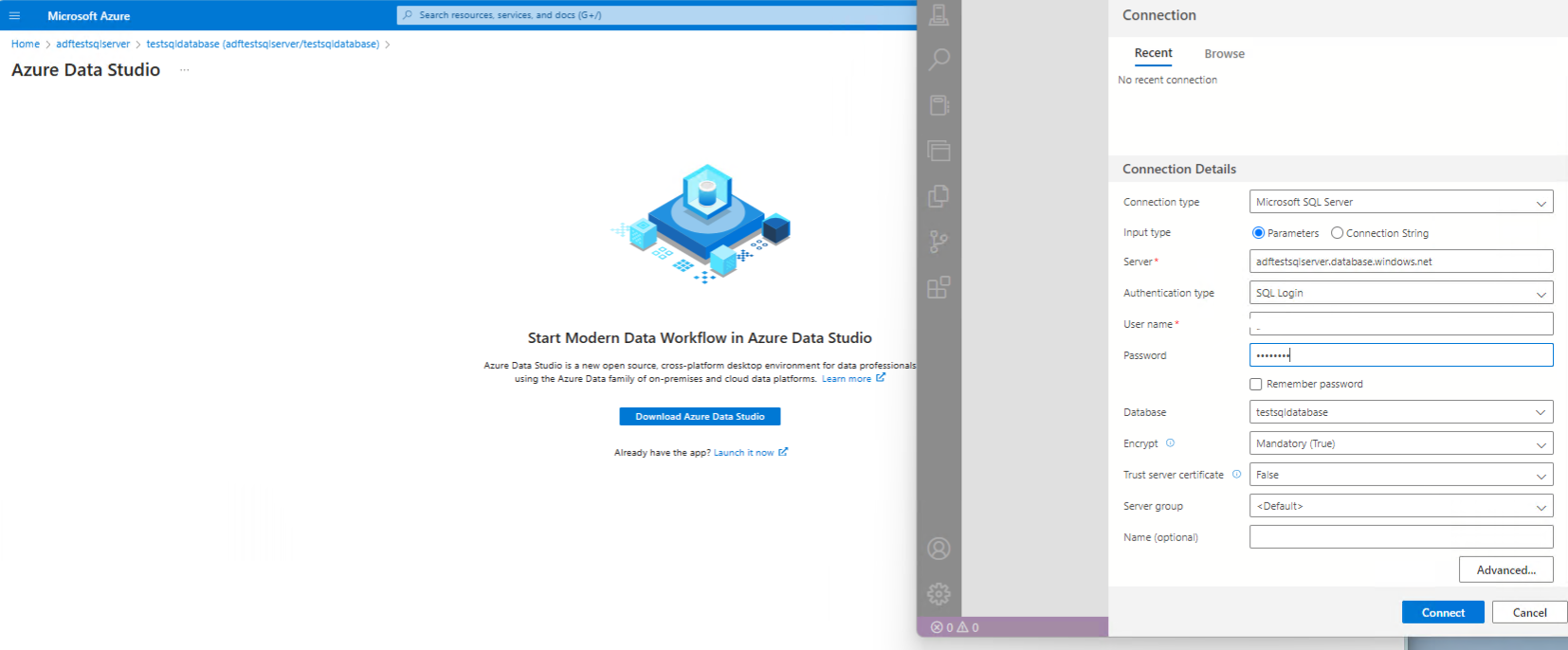
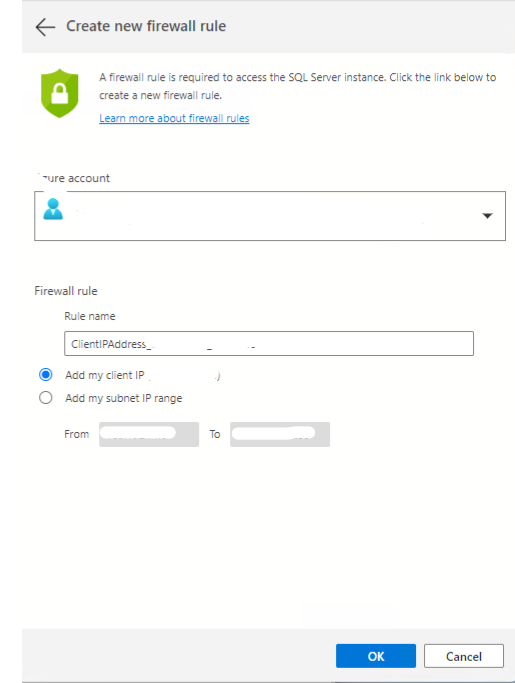
Add your acccount to the firewall rule and click ok.
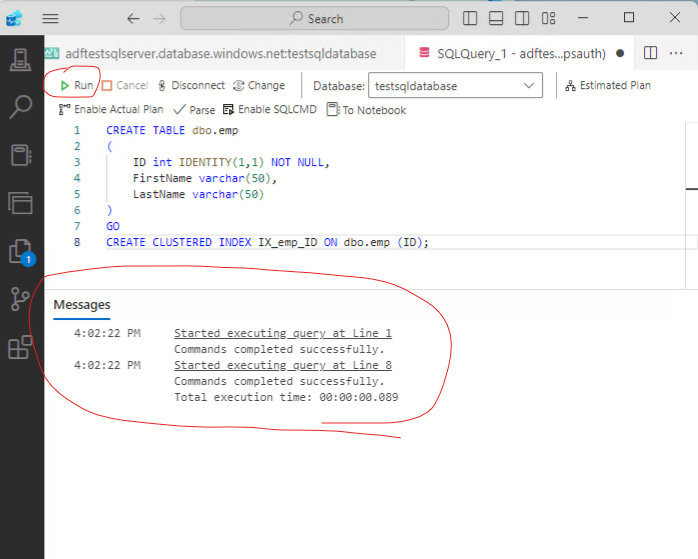
Next create a new query and run the following SQL to create a table in the database:
CREATE TABLE dbo.emp
(
ID int IDENTITY(1,1) NOT NULL,
FirstName varchar(50),
LastName varchar(50)
)
GO
CREATE CLUSTERED INDEX IX_emp_ID ON dbo.emp (ID);
Run the query to create the table.
Next create a data faqctory in the same resource group.
In the Azure portal:
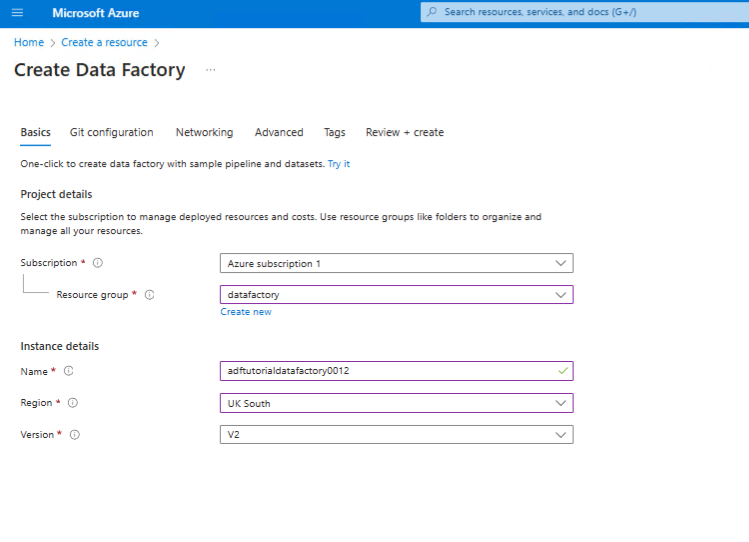
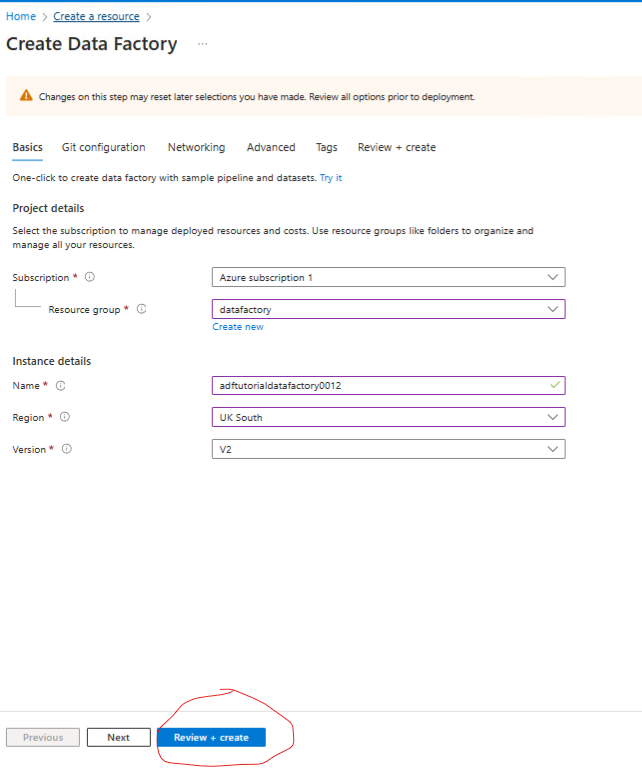
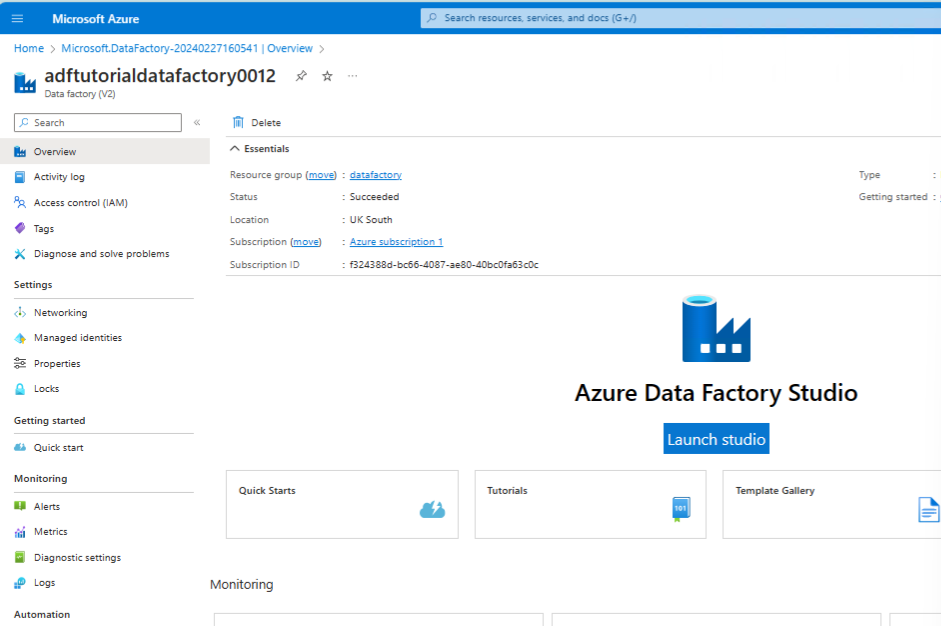
Click > Go to resource > Launch Studio
Create a pipeline
Use Copy Data tool to create a pipeline
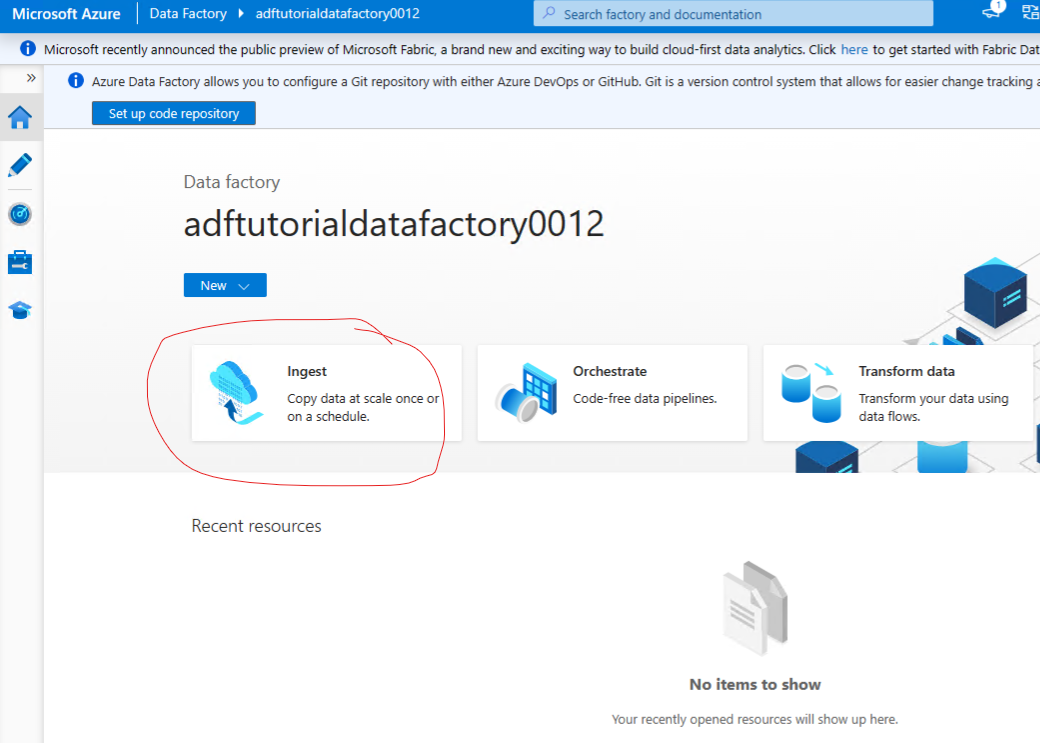
Choose built in copy task

Create source connection
Select source and Click on new connection to create a new connection.
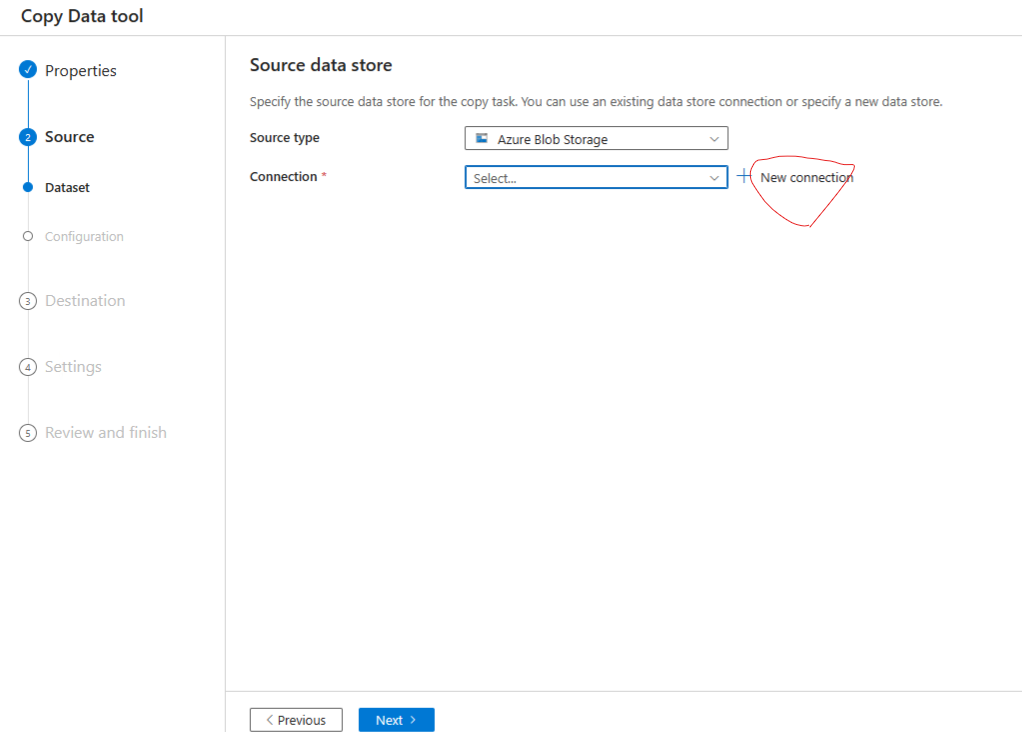
Once created test the connection and click create.
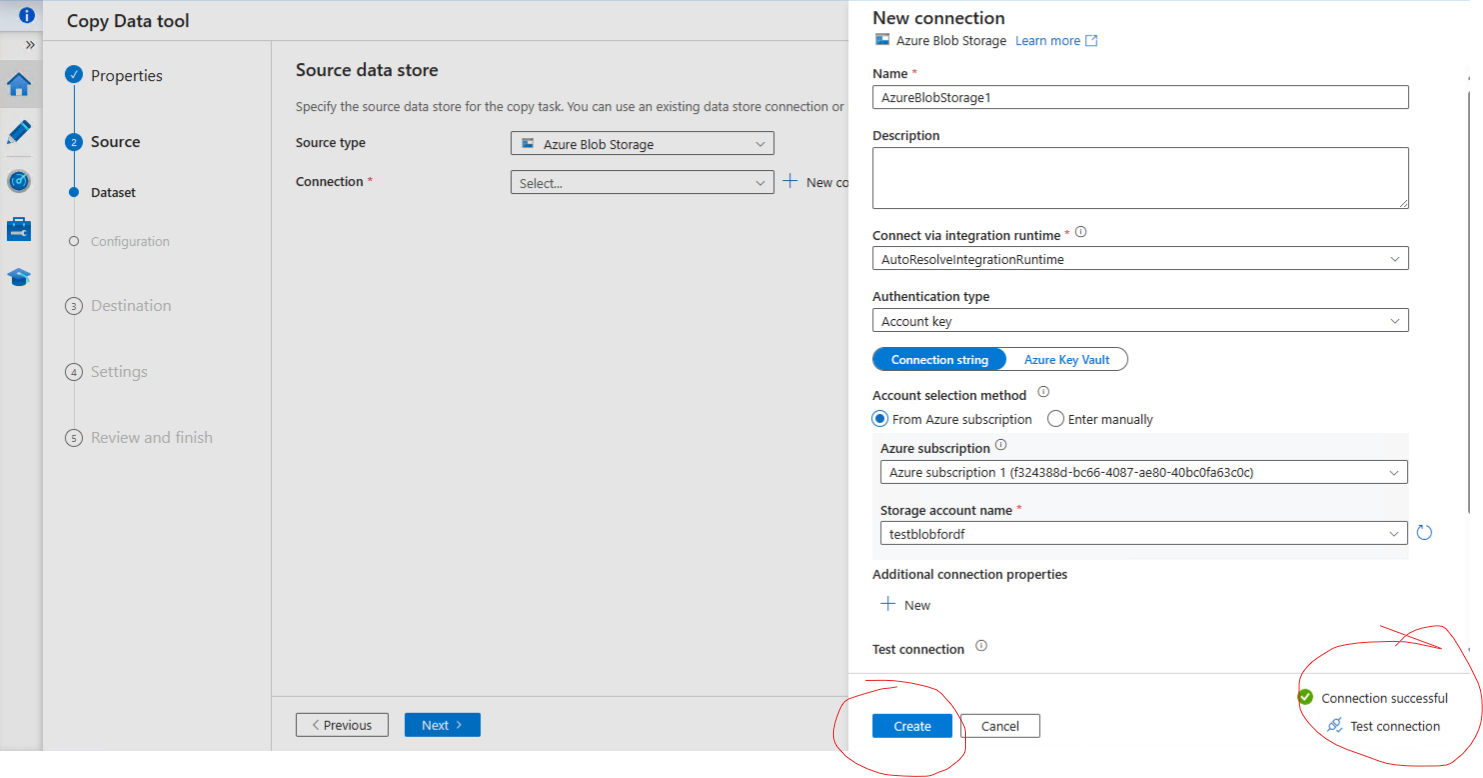
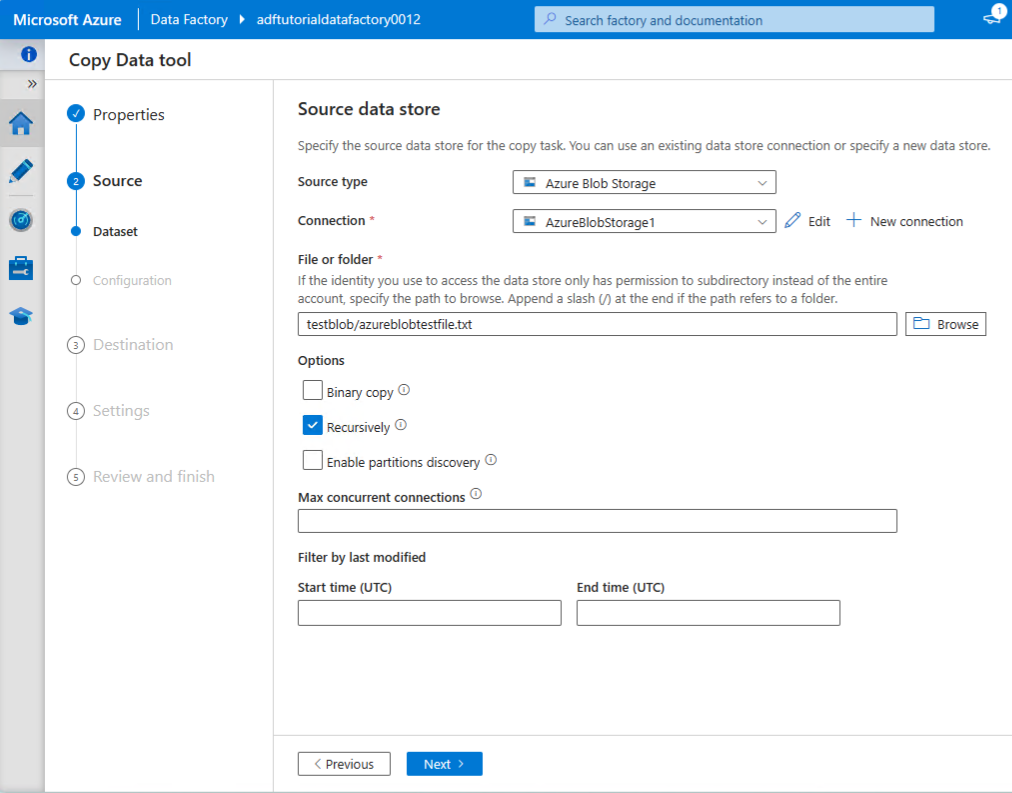
Create source data store
Point to the text file in the blob container:
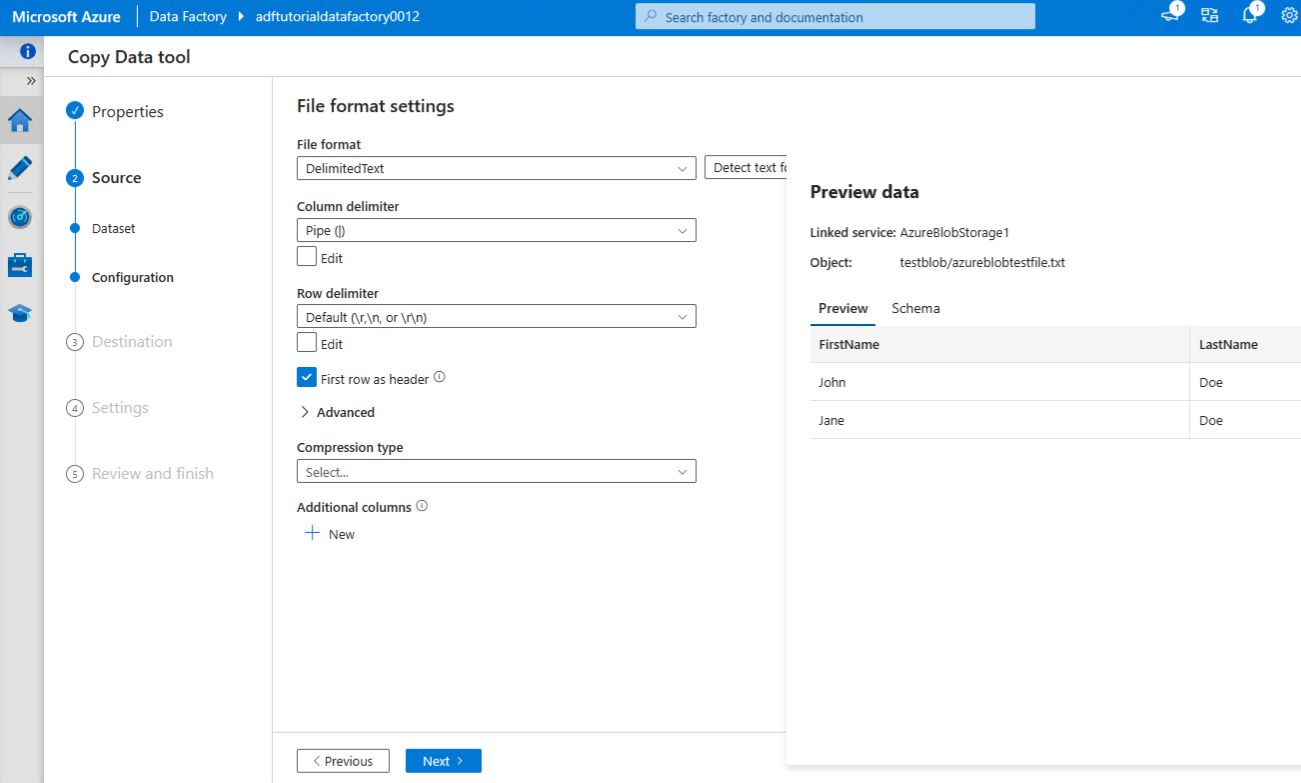
Enable first row as header and preview the data > Next
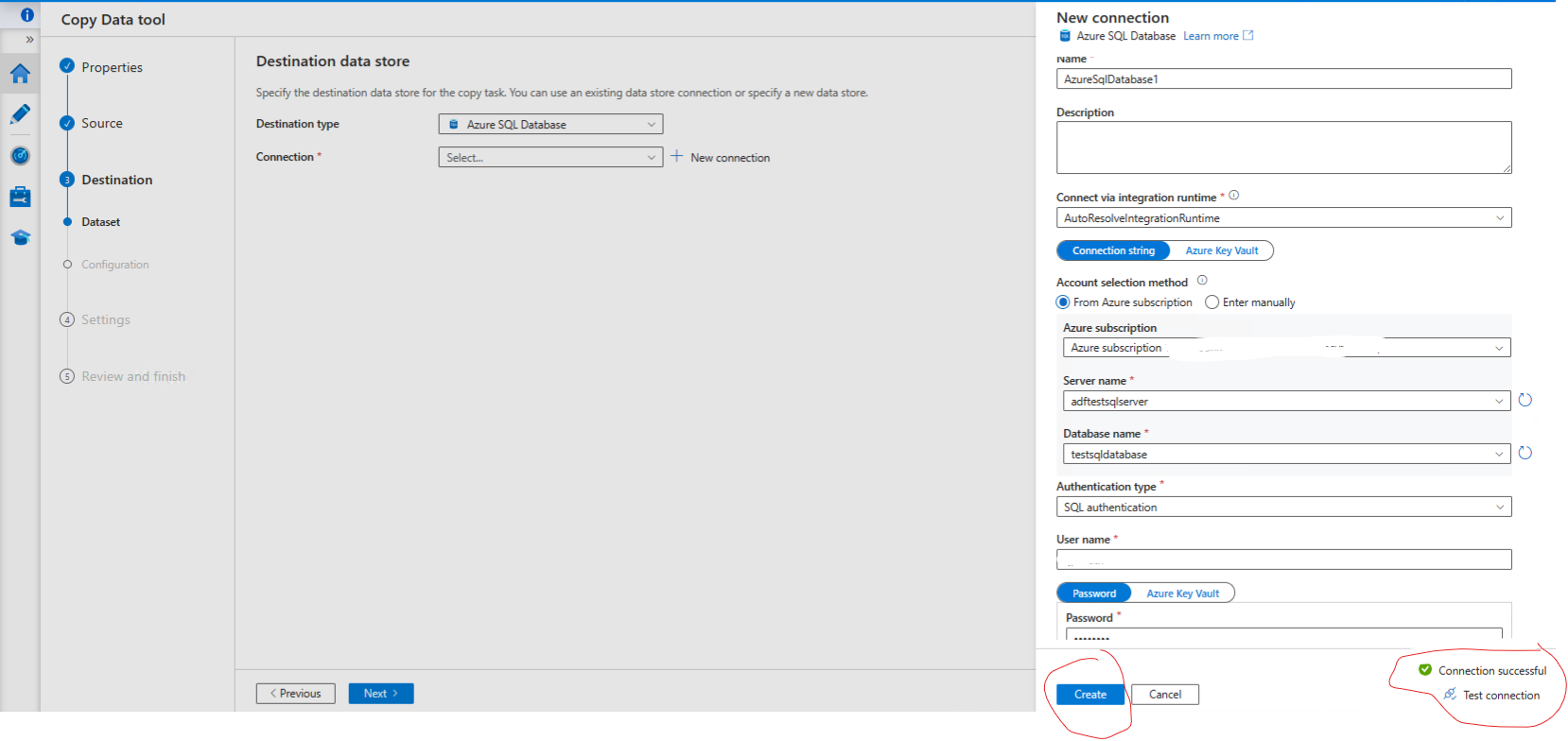
Create destination data store
Create a new connection to the SQL database - and test the connection
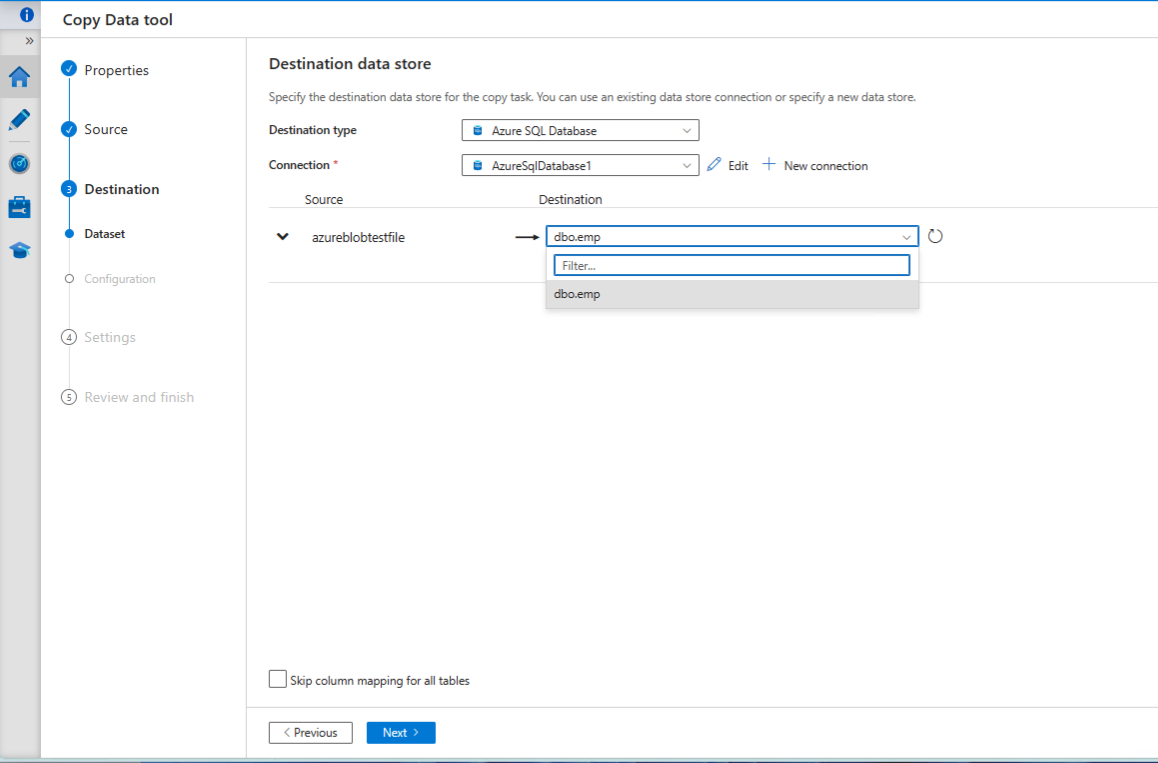
Select use existing table and choose the table created previously.
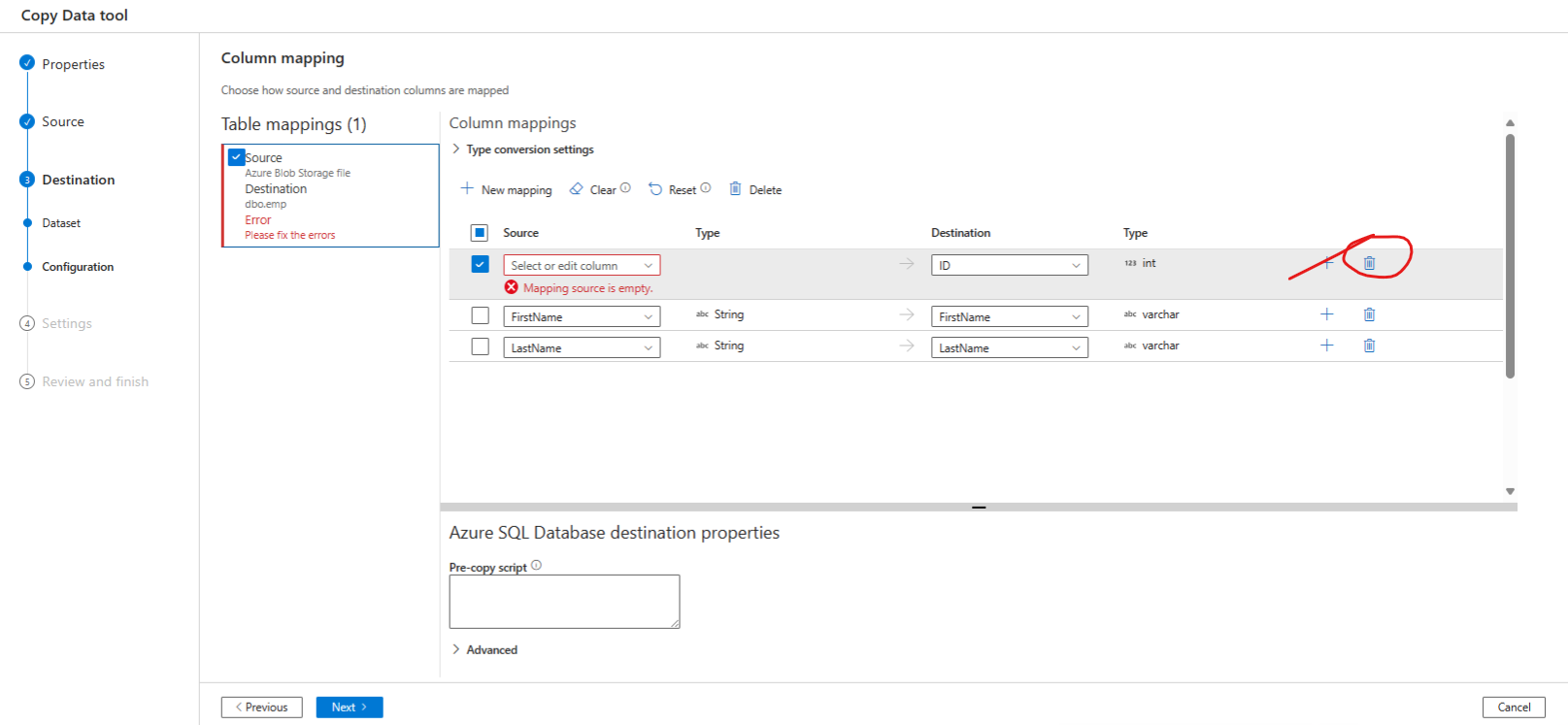
On the column mapping page - delete the id column and map the first name and last name columns:
Pipeline component
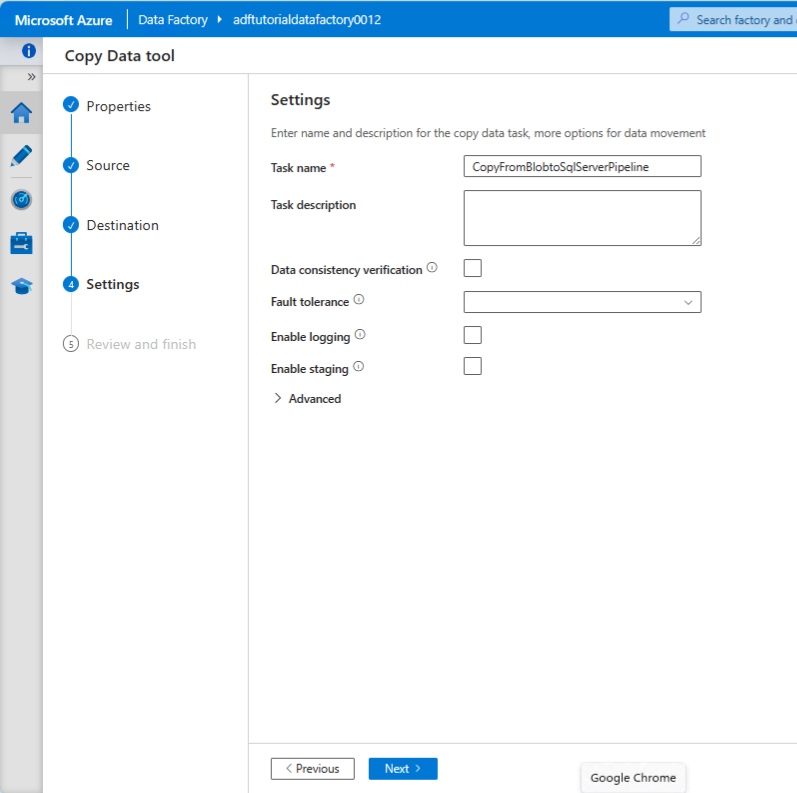
Provide a name for the pipeline (copy data tool) and click next:
Review the summary and click next:
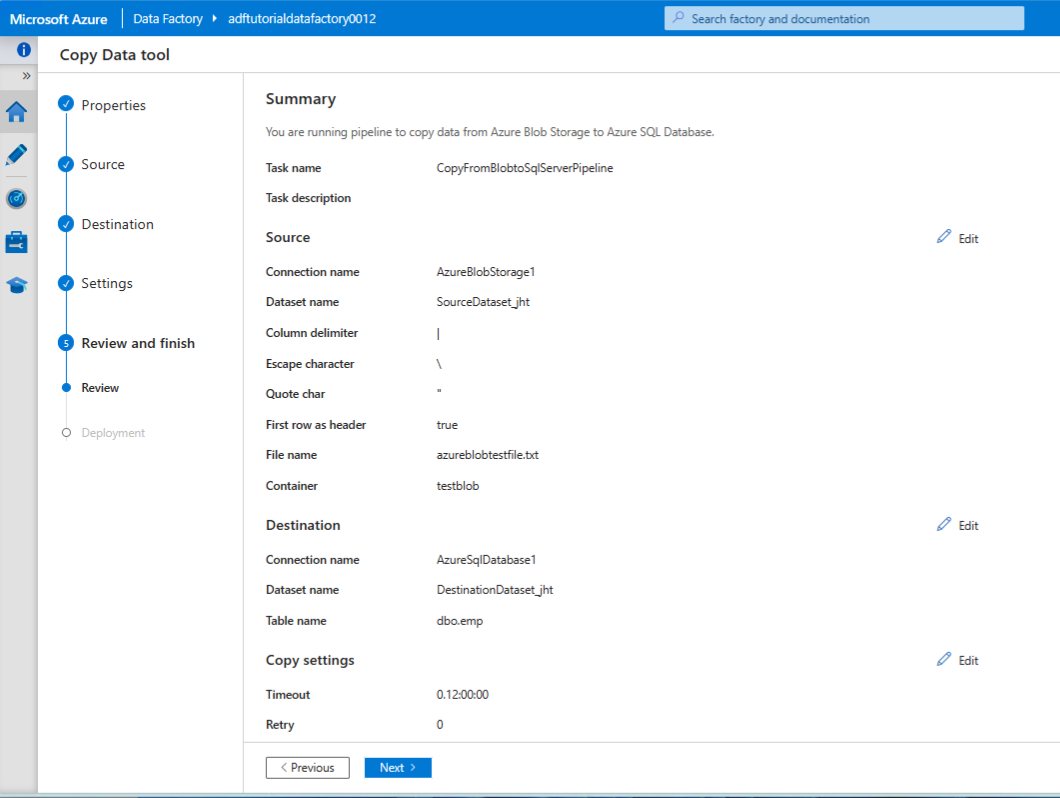
Confirm deployment complete:
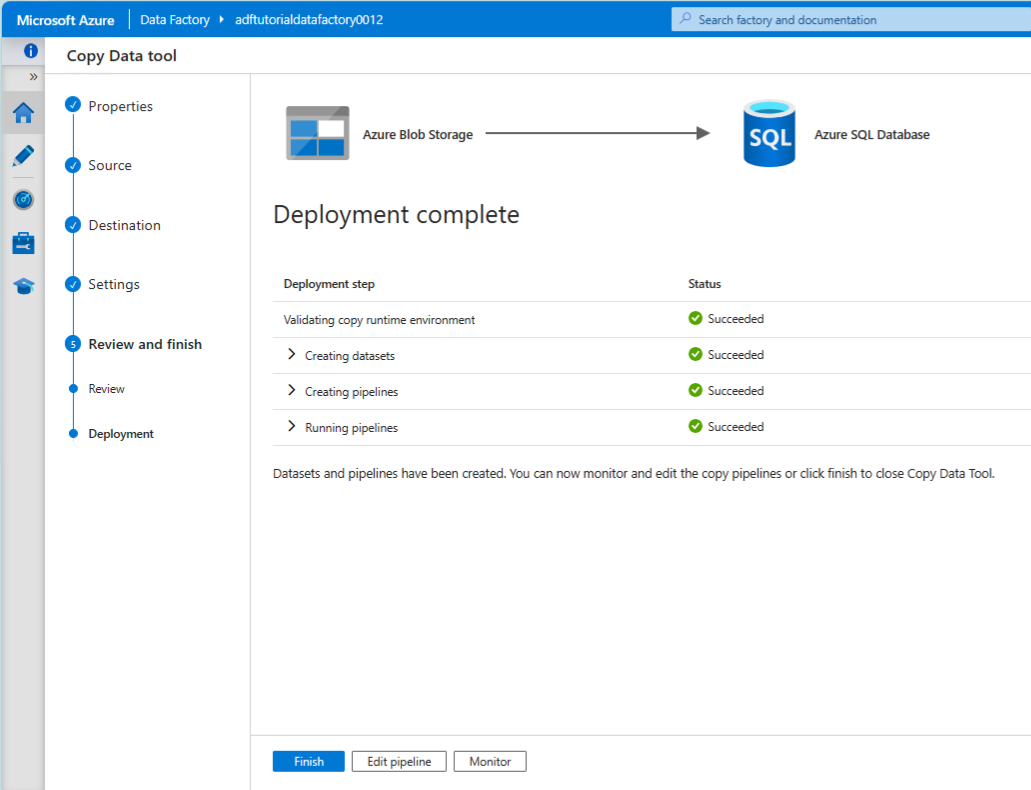
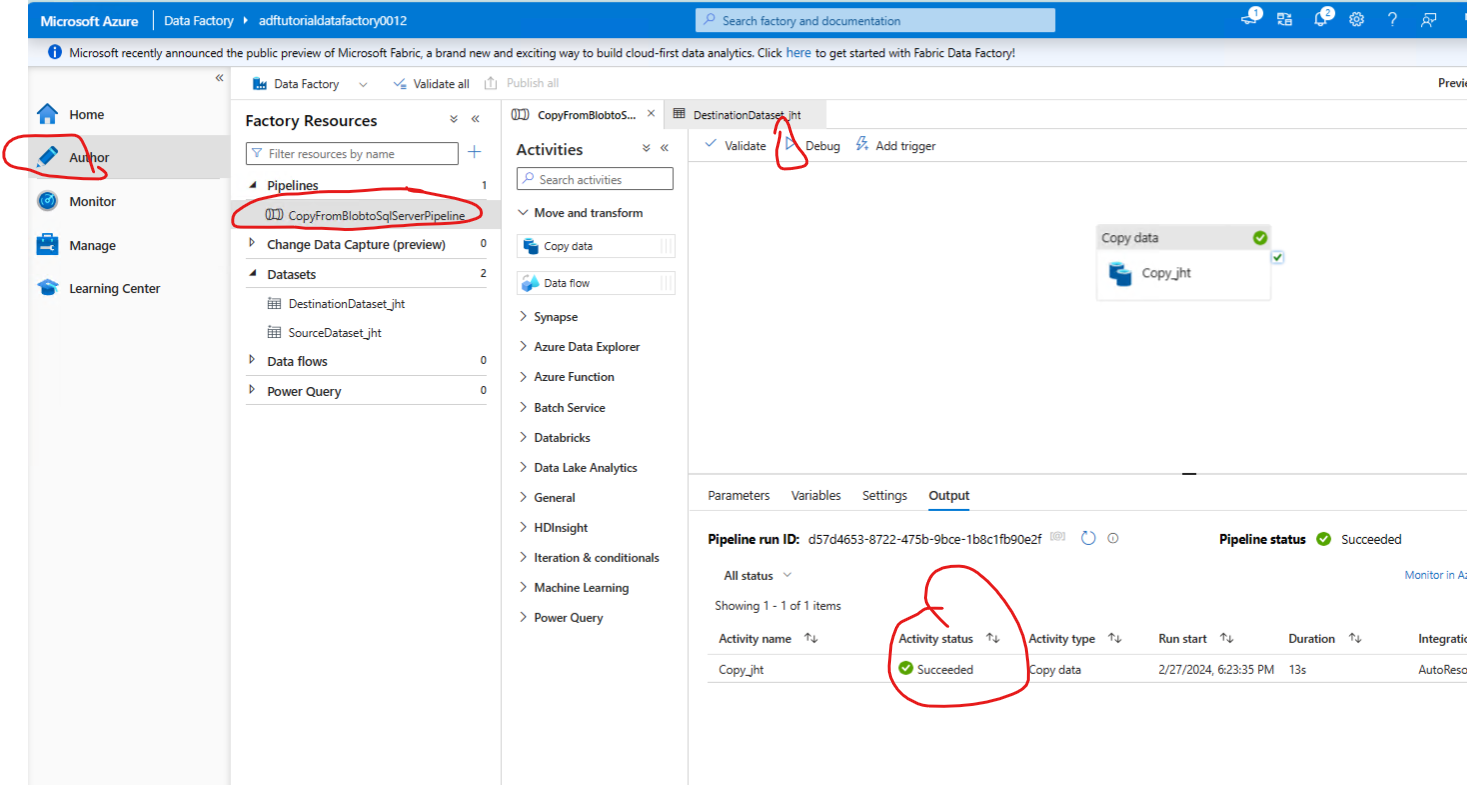
Run the pipeline
Go to Author tab, select the pipeline and run it. Confirm that run succeeded.
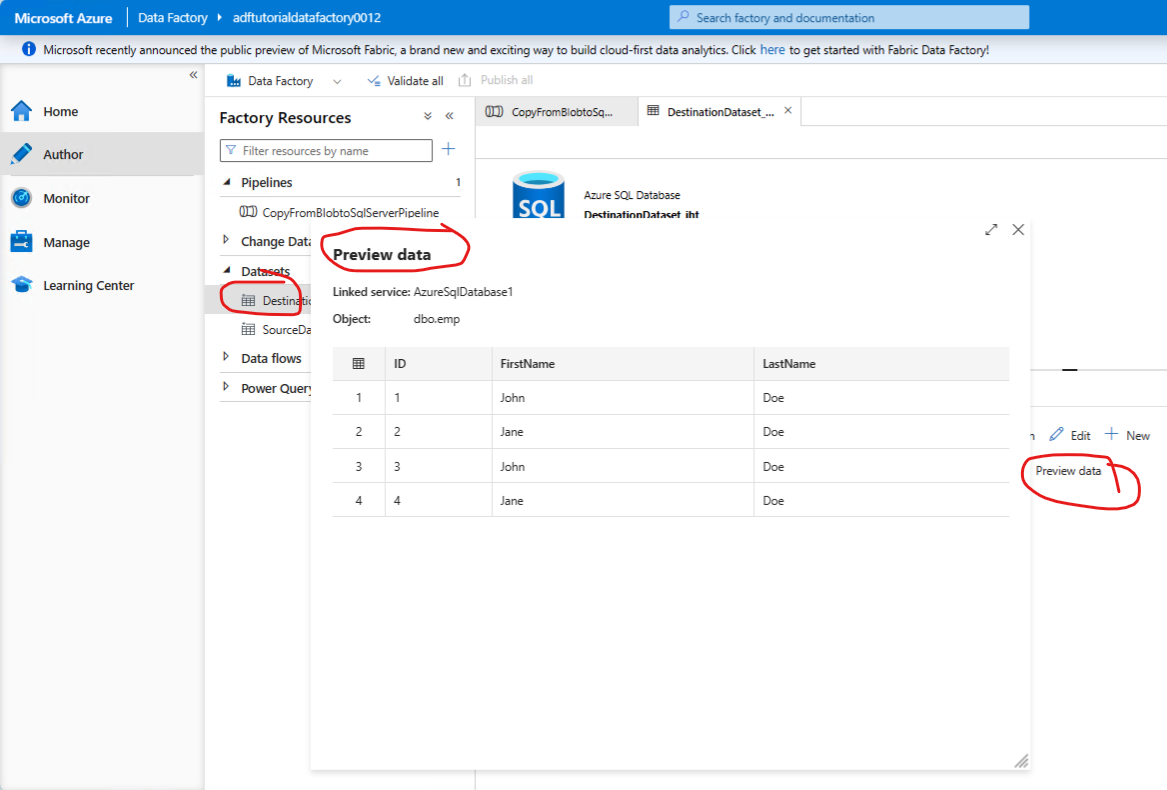
Verify the data is in the dbo.emp table in the SQL database - by selecting the destination table and running preview data:
Conclusion
In this article we have seen how to create a simple data factory pipeline to copy data from a blob storage to a SQL database. We have seen how to create the source and destination data stores, and how to use the copy data tool to create a pipeline. We have also seen how to run the pipeline and verify that the data has been copied to the destination table.
Azure Data Factory is a powerful tool for building scalable data integration solutions, and it provides a platform for creating data-driven workflows that allow you to ingest, prepare, transform, and process data from disparate sources at scale. It is a key component of the Azure data engineering ecosystem and is widely used for building data integration solutions in the cloud.